biweekly-contest-79
A
Statement
Metadata
- Link: 判断一个数的数字计数是否等于数位的值
- Difficulty: Easy
- Tag:
给你一个下标从 0 开始长度为 n 的字符串 num ,它只包含数字。
如果对于 每个 0 <= i < n 的下标 i ,都满足数位 i 在 num 中出现了 num[i]次,那么请你返回 true ,否则返回 false 。
示例 1:
输入:num = "1210"
输出:true
解释:
num[0] = '1' 。数字 0 在 num 中出现了一次。
num[1] = '2' 。数字 1 在 num 中出现了两次。
num[2] = '1' 。数字 2 在 num 中出现了一次。
num[3] = '0' 。数字 3 在 num 中出现了零次。
"1210" 满足题目要求条件,所以返回 true 。
示例 2:
输入:num = "030"
输出:false
解释:
num[0] = '0' 。数字 0 应该出现 0 次,但是在 num 中出现了一次。
num[1] = '3' 。数字 1 应该出现 3 次,但是在 num 中出现了零次。
num[2] = '0' 。数字 2 在 num 中出现了 0 次。
下标 0 和 1 都违反了题目要求,所以返回 false 。
提示:
n == num.length1 <= n <= 10num只包含数字。
Metadata
- Link: Check if Number Has Equal Digit Count and Digit Value
- Difficulty: Easy
- Tag:
You are given a 0-indexed string num of length n consisting of digits.
Return true if for every index i in the range 0 <= i < n, the digit i occurs num[i] times in num, otherwise return false.
Example 1:
Input: num = "1210"
Output: true
Explanation:
num[0] = '1'. The digit 0 occurs once in num.
num[1] = '2'. The digit 1 occurs twice in num.
num[2] = '1'. The digit 2 occurs once in num.
num[3] = '0'. The digit 3 occurs zero times in num.
The condition holds true for every index in "1210", so return true.
Example 2:
Input: num = "030"
Output: false
Explanation:
num[0] = '0'. The digit 0 should occur zero times, but actually occurs twice in num.
num[1] = '3'. The digit 1 should occur three times, but actually occurs zero times in num.
num[2] = '0'. The digit 2 occurs zero times in num.
The indices 0 and 1 both violate the condition, so return false.
Constraints:
n == num.length1 <= n <= 10numconsists of digits.
Solution
#include <bits/stdc++.h>
#include <ext/pb_ds/assoc_container.hpp>
#include <ext/pb_ds/tree_policy.hpp>
#include <vector>
#define endl "\n"
#define fi first
#define se second
#define all(x) begin(x), end(x)
#define rall rbegin(a), rend(a)
#define bitcnt(x) (__builtin_popcountll(x))
#define complete_unique(a) a.erase(unique(begin(a), end(a)), end(a))
#define mst(x, a) memset(x, a, sizeof(x))
#define MP make_pair
using ll = long long;
using ull = unsigned long long;
using db = double;
using ld = long double;
using VLL = std::vector<ll>;
using VI = std::vector<int>;
using PII = std::pair<int, int>;
using PLL = std::pair<ll, ll>;
using namespace __gnu_pbds;
using namespace std;
template <typename T>
using ordered_set = tree<T, null_type, less<T>, rb_tree_tag, tree_order_statistics_node_update>;
template <typename T, typename S>
inline bool chmax(T &a, const S &b) {
return a < b ? a = b, 1 : 0;
}
template <typename T, typename S>
inline bool chmin(T &a, const S &b) {
return a > b ? a = b, 1 : 0;
}
#ifdef LOCAL
#include <debug.hpp>
#else
#define dbg(...)
#endif
// head
class Solution {
public:
bool digitCount(string num) {
int n = num.size();
auto cnt = vector<int>(20, 0);
for (int i = 0; i < n; i++) {
++cnt[num[i] - '0'];
}
for (int i = 0; i < n; i++) {
if (cnt[i] != num[i] - '0') {
return false;
}
}
return true;
}
};
#ifdef LOCAL
int main() {
return 0;
}
#endif
B
Statement
Metadata
- Link: 最多单词数的发件人
- Difficulty: Medium
- Tag:
给你一个聊天记录,共包含 n 条信息。给你两个字符串数组 messages 和 senders ,其中 messages[i] 是 senders[i] 发出的一条 信息 。
一条 信息 是若干用单个空格连接的 单词 ,信息开头和结尾不会有多余空格。发件人的 单词计数 是这个发件人总共发出的 单词数 。注意,一个发件人可能会发出多于一条信息。
请你返回发出单词数 最多 的发件人名字。如果有多个发件人发出最多单词数,请你返回 字典序 最大的名字。
注意:
- 字典序里,大写字母小于小写字母。
"Alice"和"alice"是不同的名字。
示例 1:
输入:messages = ["Hello userTwooo","Hi userThree","Wonderful day Alice","Nice day userThree"], senders = ["Alice","userTwo","userThree","Alice"]
输出:"Alice"
解释:Alice 总共发出了 2 + 3 = 5 个单词。
userTwo 发出了 2 个单词。
userThree 发出了 3 个单词。
由于 Alice 发出单词数最多,所以我们返回 "Alice" 。
示例 2:
输入:messages = ["How is leetcode for everyone","Leetcode is useful for practice"], senders = ["Bob","Charlie"]
输出:"Charlie"
解释:Bob 总共发出了 5 个单词。
Charlie 总共发出了 5 个单词。
由于最多单词数打平,返回字典序最大的名字,也就是 Charlie 。
提示:
n == messages.length == senders.length1 <= n <= 1041 <= messages[i].length <= 1001 <= senders[i].length <= 10messages[i]包含大写字母、小写字母和' '。messages[i]中所有单词都由 单个空格 隔开。messages[i]不包含前导和后缀空格。senders[i]只包含大写英文字母和小写英文字母。
Metadata
- Link: Sender With Largest Word Count
- Difficulty: Medium
- Tag:
You have a chat log of n messages. You are given two string arrays messages and senders where messages[i] is a message sent by senders[i].
A message is list of words that are separated by a single space with no leading or trailing spaces. The word count of a sender is the total number of words sent by the sender. Note that a sender may send more than one message.
Return the sender with the largest word count. If there is more than one sender with the largest word count, return the one with the lexicographically largest name.
Note:
- Uppercase letters come before lowercase letters in lexicographical order.
"Alice"and"alice"are distinct.
Example 1:
Input: messages = ["Hello userTwooo","Hi userThree","Wonderful day Alice","Nice day userThree"], senders = ["Alice","userTwo","userThree","Alice"]
Output: "Alice"
Explanation: Alice sends a total of 2 + 3 = 5 words.
userTwo sends a total of 2 words.
userThree sends a total of 3 words.
Since Alice has the largest word count, we return "Alice".
Example 2:
Input: messages = ["How is leetcode for everyone","Leetcode is useful for practice"], senders = ["Bob","Charlie"]
Output: "Charlie"
Explanation: Bob sends a total of 5 words.
Charlie sends a total of 5 words.
Since there is a tie for the largest word count, we return the sender with the lexicographically larger name, Charlie.
Constraints:
n == messages.length == senders.length1 <= n <= 1041 <= messages[i].length <= 1001 <= senders[i].length <= 10messages[i]consists of uppercase and lowercase English letters and' '.- All the words in
messages[i]are separated by a single space. messages[i]does not have leading or trailing spaces.senders[i]consists of uppercase and lowercase English letters only.
Solution
#include <bits/stdc++.h>
#include <ext/pb_ds/assoc_container.hpp>
#include <ext/pb_ds/tree_policy.hpp>
#define endl "\n"
#define fi first
#define se second
#define all(x) begin(x), end(x)
#define rall rbegin(a), rend(a)
#define bitcnt(x) (__builtin_popcountll(x))
#define complete_unique(a) a.erase(unique(begin(a), end(a)), end(a))
#define mst(x, a) memset(x, a, sizeof(x))
#define MP make_pair
using ll = long long;
using ull = unsigned long long;
using db = double;
using ld = long double;
using VLL = std::vector<ll>;
using VI = std::vector<int>;
using PII = std::pair<int, int>;
using PLL = std::pair<ll, ll>;
using namespace __gnu_pbds;
using namespace std;
template <typename T>
using ordered_set = tree<T, null_type, less<T>, rb_tree_tag, tree_order_statistics_node_update>;
template <typename T, typename S>
inline bool chmax(T& a, const S& b) {
return a < b ? a = b, 1 : 0;
}
template <typename T, typename S>
inline bool chmin(T& a, const S& b) {
return a > b ? a = b, 1 : 0;
}
#ifdef LOCAL
#include <debug.hpp>
#else
#define dbg(...)
#endif
// head
class Solution {
public:
string largestWordCount(vector<string>& messages, vector<string>& senders) {
int n = messages.size();
map<string, int> cnt;
for (int i = 0; i < n; i++) {
int space = 0;
for (const char& c : messages[i]) {
space += (c == ' ');
}
++space;
cnt[senders[i]] = cnt[senders[i]] + space;
}
string ans;
int max_space = 0;
for (const auto& [k, v] : cnt) {
if (v >= max_space) {
ans = k;
max_space = v;
}
}
return ans;
}
};
#ifdef LOCAL
int main() {
return 0;
}
#endif
C
Statement
Metadata
- Link: 道路的最大总重要性
- Difficulty: Medium
- Tag:
给你一个整数 n ,表示一个国家里的城市数目。城市编号为 0 到 n - 1 。
给你一个二维整数数组 roads ,其中 roads[i] = [ai, bi] 表示城市 ai 和 bi 之间有一条 双向 道路。
你需要给每个城市安排一个从 1 到 n 之间的整数值,且每个值只能被使用 一次 。道路的 重要性 定义为这条道路连接的两座城市数值 之和 。
请你返回在最优安排下,所有道路重要性 之和 最大 为多少。
示例 1:
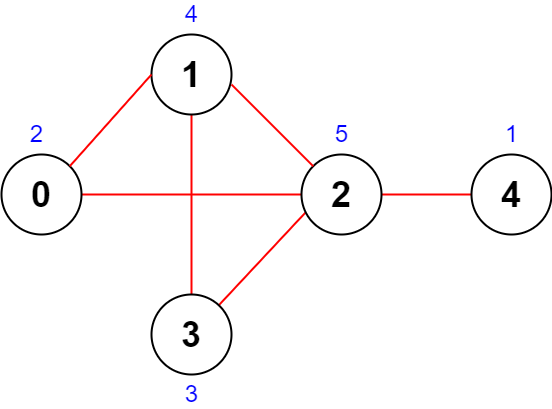
输入:n = 5, roads = [[0,1],[1,2],[2,3],[0,2],[1,3],[2,4]]
输出:43
解释:上图展示了国家图和每个城市被安排的值 [2,4,5,3,1] 。
- 道路 (0,1) 重要性为 2 + 4 = 6 。
- 道路 (1,2) 重要性为 4 + 5 = 9 。
- 道路 (2,3) 重要性为 5 + 3 = 8 。
- 道路 (0,2) 重要性为 2 + 5 = 7 。
- 道路 (1,3) 重要性为 4 + 3 = 7 。
- 道路 (2,4) 重要性为 5 + 1 = 6 。
所有道路重要性之和为 6 + 9 + 8 + 7 + 7 + 6 = 43 。
可以证明,重要性之和不可能超过 43 。
示例 2:
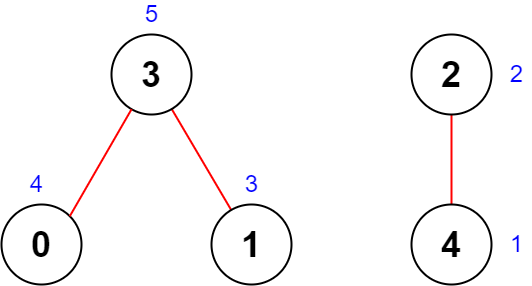
输入:n = 5, roads = [[0,3],[2,4],[1,3]]
输出:20
解释:上图展示了国家图和每个城市被安排的值 [4,3,2,5,1] 。
- 道路 (0,3) 重要性为 4 + 5 = 9 。
- 道路 (2,4) 重要性为 2 + 1 = 3 。
- 道路 (1,3) 重要性为 3 + 5 = 8 。
所有道路重要性之和为 9 + 3 + 8 = 20 。
可以证明,重要性之和不可能超过 20 。
提示:
2 <= n <= 5 * 1041 <= roads.length <= 5 * 104roads[i].length == 20 <= ai, bi <= n - 1ai != bi- 没有重复道路。
Metadata
- Link: Maximum Total Importance of Roads
- Difficulty: Medium
- Tag:
You are given an integer n denoting the number of cities in a country. The cities are numbered from 0 to n - 1.
You are also given a 2D integer array roads where roads[i] = [ai, bi] denotes that there exists a bidirectional road connecting cities ai and bi.
You need to assign each city with an integer value from 1 to n, where each value can only be used once. The importance of a road is then defined as the sum of the values of the two cities it connects.
Return the maximum total importance of all roads possible after assigning the values optimally.
Example 1:
Input: n = 5, roads = [[0,1],[1,2],[2,3],[0,2],[1,3],[2,4]]
Output: 43
Explanation: The figure above shows the country and the assigned values of [2,4,5,3,1].
- The road (0,1) has an importance of 2 + 4 = 6.
- The road (1,2) has an importance of 4 + 5 = 9.
- The road (2,3) has an importance of 5 + 3 = 8.
- The road (0,2) has an importance of 2 + 5 = 7.
- The road (1,3) has an importance of 4 + 3 = 7.
- The road (2,4) has an importance of 5 + 1 = 6.
The total importance of all roads is 6 + 9 + 8 + 7 + 7 + 6 = 43.
It can be shown that we cannot obtain a greater total importance than 43.
Example 2:
Input: n = 5, roads = [[0,3],[2,4],[1,3]]
Output: 20
Explanation: The figure above shows the country and the assigned values of [4,3,2,5,1].
- The road (0,3) has an importance of 4 + 5 = 9.
- The road (2,4) has an importance of 2 + 1 = 3.
- The road (1,3) has an importance of 3 + 5 = 8.
The total importance of all roads is 9 + 3 + 8 = 20.
It can be shown that we cannot obtain a greater total importance than 20.
Constraints:
2 <= n <= 5 * 1041 <= roads.length <= 5 * 104roads[i].length == 20 <= ai, bi <= n - 1ai != bi- There are no duplicate roads.
Solution
#include <bits/stdc++.h>
#include <ext/pb_ds/assoc_container.hpp>
#include <ext/pb_ds/tree_policy.hpp>
#include <vector>
#define endl "\n"
#define fi first
#define se second
#define all(x) begin(x), end(x)
#define rall rbegin(a), rend(a)
#define bitcnt(x) (__builtin_popcountll(x))
#define complete_unique(a) a.erase(unique(begin(a), end(a)), end(a))
#define mst(x, a) memset(x, a, sizeof(x))
#define MP make_pair
using ll = long long;
using ull = unsigned long long;
using db = double;
using ld = long double;
using VLL = std::vector<ll>;
using VI = std::vector<int>;
using PII = std::pair<int, int>;
using PLL = std::pair<ll, ll>;
using namespace __gnu_pbds;
using namespace std;
template <typename T>
using ordered_set = tree<T, null_type, less<T>, rb_tree_tag, tree_order_statistics_node_update>;
template <typename T, typename S>
inline bool chmax(T &a, const S &b) {
return a < b ? a = b, 1 : 0;
}
template <typename T, typename S>
inline bool chmin(T &a, const S &b) {
return a > b ? a = b, 1 : 0;
}
#ifdef LOCAL
#include <debug.hpp>
#else
#define dbg(...)
#endif
// head
class Solution {
public:
long long maximumImportance(int n, vector<vector<int>> &roads) {
auto cnt = vector<int>(n + 1, 0);
for (const auto &r : roads) {
++cnt[r[0]];
++cnt[r[1]];
}
sort(cnt.begin(), cnt.end());
reverse(cnt.begin(), cnt.end());
ll res = 0;
for (int i = 0, j = n; i < n; i++, j--) {
res += 1ll * j * cnt[i];
}
return res;
}
};
#ifdef LOCAL
int main() {
return 0;
}
#endif
D
Statement
Metadata
- Link: 以组为单位订音乐会的门票
- Difficulty: Hard
- Tag:
一个音乐会总共有 n 排座位,编号从 0 到 n - 1 ,每一排有 m 个座椅,编号为 0 到 m - 1 。你需要设计一个买票系统,针对以下情况进行座位安排:
- 同一组的
k位观众坐在 同一排座位,且座位连续 。 k位观众中 每一位 都有座位坐,但他们 不一定 坐在一起。
由于观众非常挑剔,所以:
- 只有当一个组里所有成员座位的排数都 小于等于
maxRow,这个组才能订座位。每一组的maxRow可能 不同 。 - 如果有多排座位可以选择,优先选择 最小 的排数。如果同一排中有多个座位可以坐,优先选择号码 最小 的。
请你实现 BookMyShow 类:
BookMyShow(int n, int m),初始化对象,n是排数,m是每一排的座位数。int[] gather(int k, int maxRow)返回长度为2的数组,表示k个成员中 第一个座位 的排数和座位编号,这k位成员必须坐在 同一排座位,且座位连续 。换言之,返回最小可能的r和c满足第r排中[c, c + k - 1]的座位都是空的,且r <= maxRow。如果 无法 安排座位,返回[]。boolean scatter(int k, int maxRow)如果组里所有k个成员 不一定 要坐在一起的前提下,都能在第0排到第maxRow排之间找到座位,那么请返回true。这种情况下,每个成员都优先找排数 最小 ,然后是座位编号最小的座位。如果不能安排所有k个成员的座位,请返回false。
示例 1:
输入:
["BookMyShow", "gather", "gather", "scatter", "scatter"]
[[2, 5], [4, 0], [2, 0], [5, 1], [5, 1]]
输出:
[null, [0, 0], [], true, false]
解释:
BookMyShow bms = new BookMyShow(2, 5); // 总共有 2 排,每排 5 个座位。
bms.gather(4, 0); // 返回 [0, 0]
// 这一组安排第 0 排 [0, 3] 的座位。
bms.gather(2, 0); // 返回 []
// 第 0 排只剩下 1 个座位。
// 所以无法安排 2 个连续座位。
bms.scatter(5, 1); // 返回 True
// 这一组安排第 0 排第 4 个座位和第 1 排 [0, 3] 的座位。
bms.scatter(5, 1); // 返回 False
// 总共只剩下 2 个座位。
提示:
1 <= n <= 5 * 1041 <= m, k <= 1090 <= maxRow <= n - 1gather和scatter总 调用次数不超过5 * 104次。
Metadata
- Link: Booking Concert Tickets in Groups
- Difficulty: Hard
- Tag:
A concert hall has n rows numbered from 0 to n - 1, each with m seats, numbered from 0 to m - 1. You need to design a ticketing system that can allocate seats in the following cases:
- If a group of
kspectators can sit together in a row. - If every member of a group of
kspectators can get a seat. They may or may not sit together.
Note that the spectators are very picky. Hence:
- They will book seats only if each member of their group can get a seat with row number less than or equal to
maxRow.maxRowcan vary from group to group. - In case there are multiple rows to choose from, the row with the smallest number is chosen. If there are multiple seats to choose in the same row, the seat with the smallest number is chosen.
Implement the BookMyShow class:
BookMyShow(int n, int m)Initializes the object withnas number of rows andmas number of seats per row.int[] gather(int k, int maxRow)Returns an array of length2denoting the row and seat number (respectively) of the first seat being allocated to thekmembers of the group, who must sit together. In other words, it returns the smallest possiblerandcsuch that all[c, c + k - 1]seats are valid and empty in rowr, andr <= maxRow. Returns[]in case it is not possible to allocate seats to the group.boolean scatter(int k, int maxRow)Returnstrueif allkmembers of the group can be allocated seats in rows0tomaxRow, who may or may not sit together. If the seats can be allocated, it allocateskseats to the group with the smallest row numbers, and the smallest possible seat numbers in each row. Otherwise, returnsfalse.
Example 1:
Input
["BookMyShow", "gather", "gather", "scatter", "scatter"]
[[2, 5], [4, 0], [2, 0], [5, 1], [5, 1]]
Output
[null, [0, 0], [], true, false]
Explanation
BookMyShow bms = new BookMyShow(2, 5); // There are 2 rows with 5 seats each
bms.gather(4, 0); // return [0, 0]
// The group books seats [0, 3] of row 0.
bms.gather(2, 0); // return []
// There is only 1 seat left in row 0,
// so it is not possible to book 2 consecutive seats.
bms.scatter(5, 1); // return True
// The group books seat 4 of row 0 and seats [0, 3] of row 1.
bms.scatter(5, 1); // return False
// There are only 2 seats left in the hall.
Constraints:
1 <= n <= 5 * 1041 <= m, k <= 1090 <= maxRow <= n - 1- At most
5 * 104calls in total will be made togatherandscatter.
Solution
#include <bits/stdc++.h>
#include <algorithm>
#include <ext/pb_ds/assoc_container.hpp>
#include <ext/pb_ds/tree_policy.hpp>
#include <vector>
#define endl "\n"
#define fi first
#define se second
#define all(x) begin(x), end(x)
#define rall rbegin(a), rend(a)
#define bitcnt(x) (__builtin_popcountll(x))
#define complete_unique(a) a.erase(unique(begin(a), end(a)), end(a))
#define mst(x, a) memset(x, a, sizeof(x))
#define MP make_pair
using ll = long long;
using ull = unsigned long long;
using db = double;
using ld = long double;
using VLL = std::vector<ll>;
using VI = std::vector<int>;
using PII = std::pair<int, int>;
using PLL = std::pair<ll, ll>;
using namespace __gnu_pbds;
using namespace std;
template <typename T>
using ordered_set = tree<T, null_type, less<T>, rb_tree_tag, tree_order_statistics_node_update>;
template <typename T, typename S>
inline bool chmax(T &a, const S &b) {
return a < b ? a = b, 1 : 0;
}
template <typename T, typename S>
inline bool chmin(T &a, const S &b) {
return a > b ? a = b, 1 : 0;
}
#ifdef LOCAL
#include <debug.hpp>
#else
#define dbg(...)
#endif
// head
template <typename T>
class FenwickTree {
public:
FenwickTree() = default;
FenwickTree(const size_t n) {
arr_.reserve(n);
}
void Init(int n) {
n_ = n;
high_bit_n_ = highBit(n_);
arr_.assign(n_ + 1, 0);
}
void Add(int x, const T &v) {
for (int i = x; i <= n_; i += lowbit(i)) {
arr_[i] += v;
}
}
// query prefix sum
T Query(int x) const {
T ret = 0;
for (int i = x; i > 0; i -= lowbit(i)) {
ret += arr_[i];
}
return ret;
}
T Query(int l, int r) const {
if (l > r) {
return 0;
}
return Query(r) - Query(l - 1);
}
T QueryKth(int k) {
T p = 0;
for (int lim = 1 << (high_bit_n_); lim; lim >>= 1) {
if (p + lim <= n_ && arr_[p + lim] < k) {
p += lim;
k -= arr_[p];
}
}
return p + 1;
}
private:
int lowbit(int x) const {
return x & -x;
}
int highBit(int x) const {
int res = 0;
while (x) {
++res;
x >>= 1;
}
return res;
}
int n_, high_bit_n_;
std::vector<T> arr_;
};
const int N = 1e5 + 10;
struct SEG {
struct node {
int cur, m;
node() {
cur = m = 0;
}
node operator+(const node &other) const {
node res = node();
res.m = max(m, other.m);
return res;
}
} t[N << 2];
int res;
void build(int id, int l, int r, int x) {
t[id] = node();
if (l == r) {
t[id].cur = x;
t[id].m = x;
return;
}
int mid = (l + r) >> 1;
build(id << 1, l, mid, x);
build(id << 1 | 1, mid + 1, r, x);
t[id] = t[id << 1] + t[id << 1 | 1];
}
void update(int id, int l, int r, int x, int v) {
if (l == r) {
t[id].cur += v;
t[id].m += v;
return;
}
int mid = (l + r) >> 1;
if (x <= mid)
update(id << 1, l, mid, x, v);
if (x > mid)
update(id << 1 | 1, mid + 1, r, x, v);
t[id] = t[id << 1] + t[id << 1 | 1];
}
void query(int id, int l, int r, int ql, int qr, int v) {
if (l > qr) {
return;
}
if (t[id].m < v) {
return;
}
if (l == r) {
// cout << t[id].cur << endl;
res = l;
return;
}
int mid = (l + r) >> 1;
if (t[id << 1].m >= v) {
query(id << 1, l, mid, ql, qr, v);
} else if (t[id << 1 | 1].m >= v) {
query(id << 1 | 1, mid + 1, r, ql, qr, v);
}
}
} seg;
class BookMyShow {
public:
vector<int> v;
int n, m;
FenwickTree<ll> t;
int start;
BookMyShow(int n, int m) {
this->n = n;
this->m = m;
start = 1;
v = vector<int>(n + 1, m);
t.Init(n + 1);
for (int i = 1; i <= n; i++) {
t.Add(i, m);
}
seg.build(1, 1, n, m);
}
vector<int> gather(int k, int maxRow) {
seg.res = -1;
seg.query(1, 1, n, 1, maxRow + 1, k);
int pos = seg.res;
if (pos == -1) {
return vector<int>();
}
// cout << pos << " " << v[pos] << endl;
int h = m - v[pos];
v[pos] -= k;
t.Add(pos, -k);
seg.update(1, 1, n, pos, -k);
return vector<int>({pos - 1, h});
}
bool scatter(int k, int maxRow) {
ll tot = t.Query(1, maxRow + 1);
if (tot < k) {
return false;
}
while (k > 0) {
if (v[start] > k) {
v[start] -= k;
t.Add(start, -k);
seg.update(1, 1, n, start, -k);
break;
} else {
k -= v[start];
t.Add(start, -v[start]);
seg.update(1, 1, n, start, -v[start]);
v[start] = 0;
start++;
}
}
return true;
}
};
/**
* Your BookMyShow object will be instantiated and called as such:
* BookMyShow* obj = new BookMyShow(n, m);
* vector<int> param_1 = obj->gather(k,maxRow);
* bool param_2 = obj->scatter(k,maxRow);
*/
#ifdef LOCAL
int main() {
return 0;
}
#endif