weekly-contest-303
A
Statement
Metadata
- Link: 第一个出现两次的字母
- Difficulty: Easy
- Tag:
给你一个由小写英文字母组成的字符串 s ,请你找出并返回第一个出现 两次 的字母。
注意:
- 如果
a的 第二次 出现比b的 第二次 出现在字符串中的位置更靠前,则认为字母a在字母b之前出现两次。 s包含至少一个出现两次的字母。
示例 1:
输入:s = "abccbaacz"
输出:"c"
解释:
字母 'a' 在下标 0 、5 和 6 处出现。
字母 'b' 在下标 1 和 4 处出现。
字母 'c' 在下标 2 、3 和 7 处出现。
字母 'z' 在下标 8 处出现。
字母 'c' 是第一个出现两次的字母,因为在所有字母中,'c' 第二次出现的下标是最小的。
示例 2:
输入:s = "abcdd"
输出:"d"
解释:
只有字母 'd' 出现两次,所以返回 'd' 。
提示:
2 <= s.length <= 100s由小写英文字母组成s包含至少一个重复字母
Metadata
- Link: First Letter to Appear Twice
- Difficulty: Easy
- Tag:
Given a string s consisting of lowercase English letters, return the first letter to appear twice.
Note:
- A letter
aappears twice before another letterbif the second occurrence ofais before the second occurrence ofb. swill contain at least one letter that appears twice.
Example 1:
Input: s = "abccbaacz"
Output: "c"
Explanation:
The letter 'a' appears on the indexes 0, 5 and 6.
The letter 'b' appears on the indexes 1 and 4.
The letter 'c' appears on the indexes 2, 3 and 7.
The letter 'z' appears on the index 8.
The letter 'c' is the first letter to appear twice, because out of all the letters the index of its second occurrence is the smallest.
Example 2:
Input: s = "abcdd"
Output: "d"
Explanation:
The only letter that appears twice is 'd' so we return 'd'.
Constraints:
2 <= s.length <= 100sconsists of lowercase English letters.shas at least one repeated letter.
Solution
#include <bits/stdc++.h>
#include <ext/pb_ds/assoc_container.hpp>
#include <ext/pb_ds/tree_policy.hpp>
#include <vector>
#define endl "\n"
#define fi first
#define se second
#define all(x) begin(x), end(x)
#define rall rbegin(a), rend(a)
#define bitcnt(x) (__builtin_popcountll(x))
#define complete_unique(a) a.erase(unique(begin(a), end(a)), end(a))
#define mst(x, a) memset(x, a, sizeof(x))
#define MP make_pair
using ll = long long;
using ull = unsigned long long;
using db = double;
using ld = long double;
using VLL = std::vector<ll>;
using VI = std::vector<int>;
using PII = std::pair<int, int>;
using PLL = std::pair<ll, ll>;
using namespace __gnu_pbds;
using namespace std;
template <typename T>
using ordered_set = tree<T, null_type, less<T>, rb_tree_tag, tree_order_statistics_node_update>;
template <typename T, typename S>
inline bool chmax(T &a, const S &b) {
return a < b ? a = b, 1 : 0;
}
template <typename T, typename S>
inline bool chmin(T &a, const S &b) {
return a > b ? a = b, 1 : 0;
}
#ifdef LOCAL
#include <debug.hpp>
#else
#define dbg(...)
#endif
// head
class Solution {
public:
char repeatedCharacter(string s) {
auto f = vector<int>(30, 0);
for (const auto &c : s) {
int ix = c - 'a';
f[ix]++;
if (f[ix] > 1) {
return c;
}
}
return 'a';
}
};
#ifdef LOCAL
int main() {
return 0;
}
#endif
B
Statement
Metadata
- Link: 相等行列对
- Difficulty: Medium
- Tag:
给你一个下标从 0 开始、大小为 n x n 的整数矩阵 grid ,返回满足 Ri 行和 Cj 列相等的行列对 (Ri, Cj) 的数目。
如果行和列以相同的顺序包含相同的元素(即相等的数组),则认为二者是相等的。
示例 1:
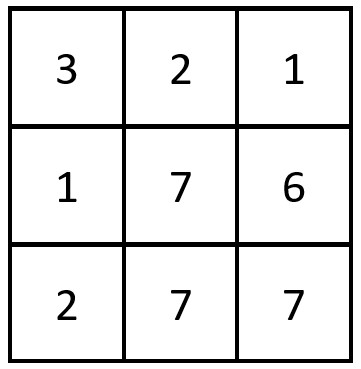
输入:grid = [[3,2,1],[1,7,6],[2,7,7]]
输出:1
解释:存在一对相等行列对:
- (第 2 行,第 1 列):[2,7,7]
示例 2:
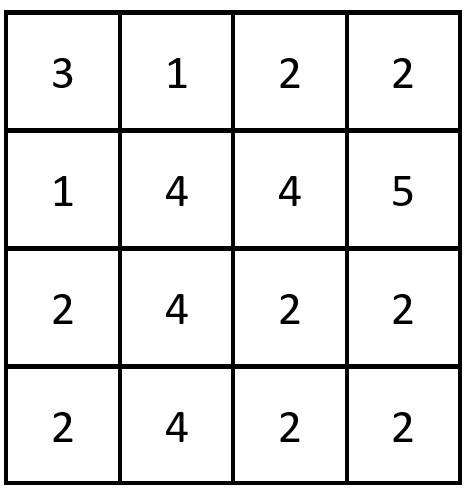
输入:grid = [[3,1,2,2],[1,4,4,5],[2,4,2,2],[2,4,2,2]]
输出:3
解释:存在三对相等行列对:
- (第 0 行,第 0 列):[3,1,2,2]
- (第 2 行, 第 2 列):[2,4,2,2]
- (第 3 行, 第 2 列):[2,4,2,2]
提示:
n == grid.length == grid[i].length1 <= n <= 2001 <= grid[i][j] <= 105
Metadata
- Link: Equal Row and Column Pairs
- Difficulty: Medium
- Tag:
Given a 0-indexed n x n integer matrix grid, return the number of pairs (Ri, Cj) such that row Ri and column Cj are equal.
A row and column pair is considered equal if they contain the same elements in the same order (i.e. an equal array).
Example 1:
Input: grid = [[3,2,1],[1,7,6],[2,7,7]]
Output: 1
Explanation: There is 1 equal row and column pair:
- (Row 2, Column 1): [2,7,7]
Example 2:
Input: grid = [[3,1,2,2],[1,4,4,5],[2,4,2,2],[2,4,2,2]]
Output: 3
Explanation: There are 3 equal row and column pairs:
- (Row 0, Column 0): [3,1,2,2]
- (Row 2, Column 2): [2,4,2,2]
- (Row 3, Column 2): [2,4,2,2]
Constraints:
n == grid.length == grid[i].length1 <= n <= 2001 <= grid[i][j] <= 105
Solution
#include <bits/stdc++.h>
#include <ext/pb_ds/assoc_container.hpp>
#include <ext/pb_ds/tree_policy.hpp>
#define endl "\n"
#define fi first
#define se second
#define all(x) begin(x), end(x)
#define rall rbegin(a), rend(a)
#define bitcnt(x) (__builtin_popcountll(x))
#define complete_unique(a) a.erase(unique(begin(a), end(a)), end(a))
#define mst(x, a) memset(x, a, sizeof(x))
#define MP make_pair
using ll = long long;
using ull = unsigned long long;
using db = double;
using ld = long double;
using VLL = std::vector<ll>;
using VI = std::vector<int>;
using PII = std::pair<int, int>;
using PLL = std::pair<ll, ll>;
using namespace __gnu_pbds;
using namespace std;
template <typename T>
using ordered_set = tree<T, null_type, less<T>, rb_tree_tag, tree_order_statistics_node_update>;
template <typename T, typename S>
inline bool chmax(T &a, const S &b) {
return a < b ? a = b, 1 : 0;
}
template <typename T, typename S>
inline bool chmin(T &a, const S &b) {
return a > b ? a = b, 1 : 0;
}
#ifdef LOCAL
#include <debug.hpp>
#else
#define dbg(...)
#endif
// head
class Solution {
public:
int equalPairs(vector<vector<int>> &grid) {
int n = int(grid.size());
int res = 0;
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
bool ok = true;
for (int k = 0; k < n; k++) {
if (grid[i][k] != grid[k][j]) {
ok = false;
break;
}
}
res += ok;
}
}
return res;
}
};
#ifdef LOCAL
int main() {
return 0;
}
#endif
C
Statement
Metadata
- Link: 设计食物评分系统
- Difficulty: Medium
- Tag:
设计一个支持下述操作的食物评分系统:
- 修改 系统中列出的某种食物的评分。
- 返回系统中某一类烹饪方式下评分最高的食物。
实现 FoodRatings 类:
FoodRatings(String[] foods, String[] cuisines, int[] ratings)初始化系统。食物由foods、cuisines和ratings描述,长度均为n。foods[i]是第i种食物的名字。cuisines[i]是第i种食物的烹饪方式。ratings[i]是第i种食物的最初评分。
void changeRating(String food, int newRating)修改名字为food的食物的评分。String highestRated(String cuisine)返回指定烹饪方式cuisine下评分最高的食物的名字。如果存在并列,返回 字典序较小 的名字。
注意,字符串 x 的字典序比字符串 y 更小的前提是:x 在字典中出现的位置在 y 之前,也就是说,要么 x 是 y 的前缀,或者在满足 x[i] != y[i] 的第一个位置 i 处,x[i] 在字母表中出现的位置在 y[i] 之前。
示例:
输入
["FoodRatings", "highestRated", "highestRated", "changeRating", "highestRated", "changeRating", "highestRated"]
[[["kimchi", "miso", "sushi", "moussaka", "ramen", "bulgogi"], ["korean", "japanese", "japanese", "greek", "japanese", "korean"], [9, 12, 8, 15, 14, 7]], ["korean"], ["japanese"], ["sushi", 16], ["japanese"], ["ramen", 16], ["japanese"]]
输出
[null, "kimchi", "ramen", null, "sushi", null, "ramen"]
解释
FoodRatings foodRatings = new FoodRatings(["kimchi", "miso", "sushi", "moussaka", "ramen", "bulgogi"], ["korean", "japanese", "japanese", "greek", "japanese", "korean"], [9, 12, 8, 15, 14, 7]);
foodRatings.highestRated("korean"); // 返回 "kimchi"
// "kimchi" 是分数最高的韩式料理,评分为 9 。
foodRatings.highestRated("japanese"); // 返回 "ramen"
// "ramen" 是分数最高的日式料理,评分为 14 。
foodRatings.changeRating("sushi", 16); // "sushi" 现在评分变更为 16 。
foodRatings.highestRated("japanese"); // 返回 "sushi"
// "sushi" 是分数最高的日式料理,评分为 16 。
foodRatings.changeRating("ramen", 16); // "ramen" 现在评分变更为 16 。
foodRatings.highestRated("japanese"); // 返回 "ramen"
// "sushi" 和 "ramen" 的评分都是 16 。
// 但是,"ramen" 的字典序比 "sushi" 更小。
提示:
1 <= n <= 2 * 104n == foods.length == cuisines.length == ratings.length1 <= foods[i].length, cuisines[i].length <= 10foods[i]、cuisines[i]由小写英文字母组成1 <= ratings[i] <= 108foods中的所有字符串 互不相同- 在对
changeRating的所有调用中,food是系统中食物的名字。 - 在对
highestRated的所有调用中,cuisine是系统中 至少一种 食物的烹饪方式。 - 最多调用
changeRating和highestRated总计2 * 104次
Metadata
- Link: Design a Food Rating System
- Difficulty: Medium
- Tag:
Design a food rating system that can do the following:
- Modify the rating of a food item listed in the system.
- Return the highest-rated food item for a type of cuisine in the system.
Implement the FoodRatings class:
FoodRatings(String[] foods, String[] cuisines, int[] ratings)Initializes the system. The food items are described byfoods,cuisinesandratings, all of which have a length ofn.foods[i]is the name of theithfood,cuisines[i]is the type of cuisine of theithfood, andratings[i]is the initial rating of theithfood.
void changeRating(String food, int newRating)Changes the rating of the food item with the namefood.String highestRated(String cuisine)Returns the name of the food item that has the highest rating for the given type ofcuisine. If there is a tie, return the item with the lexicographically smaller name.
Note that a string x is lexicographically smaller than string y if x comes before y in dictionary order, that is, either x is a prefix of y, or if i is the first position such that x[i] != y[i], then x[i] comes before y[i] in alphabetic order.
Example 1:
Input
["FoodRatings", "highestRated", "highestRated", "changeRating", "highestRated", "changeRating", "highestRated"]
[[["kimchi", "miso", "sushi", "moussaka", "ramen", "bulgogi"], ["korean", "japanese", "japanese", "greek", "japanese", "korean"], [9, 12, 8, 15, 14, 7]], ["korean"], ["japanese"], ["sushi", 16], ["japanese"], ["ramen", 16], ["japanese"]]
Output
[null, "kimchi", "ramen", null, "sushi", null, "ramen"]
Explanation
FoodRatings foodRatings = new FoodRatings(["kimchi", "miso", "sushi", "moussaka", "ramen", "bulgogi"], ["korean", "japanese", "japanese", "greek", "japanese", "korean"], [9, 12, 8, 15, 14, 7]);
foodRatings.highestRated("korean"); // return "kimchi"
// "kimchi" is the highest rated korean food with a rating of 9.
foodRatings.highestRated("japanese"); // return "ramen"
// "ramen" is the highest rated japanese food with a rating of 14.
foodRatings.changeRating("sushi", 16); // "sushi" now has a rating of 16.
foodRatings.highestRated("japanese"); // return "sushi"
// "sushi" is the highest rated japanese food with a rating of 16.
foodRatings.changeRating("ramen", 16); // "ramen" now has a rating of 16.
foodRatings.highestRated("japanese"); // return "ramen"
// Both "sushi" and "ramen" have a rating of 16.
// However, "ramen" is lexicographically smaller than "sushi".
Constraints:
1 <= n <= 2 * 104n == foods.length == cuisines.length == ratings.length1 <= foods[i].length, cuisines[i].length <= 10foods[i],cuisines[i]consist of lowercase English letters.1 <= ratings[i] <= 108- All the strings in
foodsare distinct. foodwill be the name of a food item in the system across all calls tochangeRating.cuisinewill be a type of cuisine of at least one food item in the system across all calls tohighestRated.- At most
2 * 104calls in total will be made tochangeRatingandhighestRated.
Solution
#include <bits/stdc++.h>
#include <ext/pb_ds/assoc_container.hpp>
#include <ext/pb_ds/tree_policy.hpp>
#define endl "\n"
#define fi first
#define se second
#define all(x) begin(x), end(x)
#define rall rbegin(a), rend(a)
#define bitcnt(x) (__builtin_popcountll(x))
#define complete_unique(a) a.erase(unique(begin(a), end(a)), end(a))
#define mst(x, a) memset(x, a, sizeof(x))
#define MP make_pair
using ll = long long;
using ull = unsigned long long;
using db = double;
using ld = long double;
using VLL = std::vector<ll>;
using VI = std::vector<int>;
using PII = std::pair<int, int>;
using PLL = std::pair<ll, ll>;
using namespace __gnu_pbds;
using namespace std;
template <typename T>
using ordered_set = tree<T, null_type, less<T>, rb_tree_tag, tree_order_statistics_node_update>;
template <typename T, typename S>
inline bool chmax(T& a, const S& b) {
return a < b ? a = b, 1 : 0;
}
template <typename T, typename S>
inline bool chmin(T& a, const S& b) {
return a > b ? a = b, 1 : 0;
}
#ifdef LOCAL
#include <debug.hpp>
#else
#define dbg(...)
#endif
// head
struct node {
int rating;
std::string name;
bool operator<(const node& other) const {
if (rating != other.rating) {
return rating > other.rating;
}
return name < other.name;
}
};
class FoodRatings {
public:
FoodRatings(vector<string>& foods, vector<string>& cuisines, vector<int>& ratings) {
int n = int(foods.size());
for (int i = 0; i < n; i++) {
f_c_map[foods[i]] = {cuisines[i], ratings[i]};
c_map[cuisines[i]].insert({ratings[i], foods[i]});
}
}
void changeRating(string food, int newRating) {
const auto& [c, r] = f_c_map[food];
c_map[c].erase({r, food});
c_map[c].insert({newRating, food});
f_c_map[food] = {c, newRating};
}
string highestRated(string cuisine) {
auto it = c_map[cuisine].begin();
return it->name;
}
map<string, pair<string, int>> f_c_map;
map<string, set<node>> c_map;
};
/**
* Your FoodRatings object will be instantiated and called as such:
* FoodRatings* obj = new FoodRatings(foods, cuisines, ratings);
* obj->changeRating(food,newRating);
* string param_2 = obj->highestRated(cuisine);
*/
#ifdef LOCAL
int main() {
return 0;
}
#endif
D
Statement
Metadata
- Link: 优质数对的数目
- Difficulty: Hard
- Tag:
给你一个下标从 0 开始的正整数数组 nums 和一个正整数 k 。
如果满足下述条件,则数对 (num1, num2) 是 优质数对 :
num1和num2都 在数组nums中存在。num1 OR num2和num1 AND num2的二进制表示中值为 1 的位数之和大于等于k,其中OR是按位 或 操作,而AND是按位 与 操作。
返回 不同 优质数对的数目。
如果 a != c 或者 b != d ,则认为 (a, b) 和 (c, d) 是不同的两个数对。例如,(1, 2) 和 (2, 1) 不同。
注意:如果 num1 在数组中至少出现 一次 ,则满足 num1 == num2 的数对 (num1, num2) 也可以是优质数对。
示例 1:
输入:nums = [1,2,3,1], k = 3
输出:5
解释:有如下几个优质数对:
- (3, 3):(3 AND 3) 和 (3 OR 3) 的二进制表示都等于 (11) 。值为 1 的位数和等于 2 + 2 = 4 ,大于等于 k = 3 。
- (2, 3) 和 (3, 2): (2 AND 3) 的二进制表示等于 (10) ,(2 OR 3) 的二进制表示等于 (11) 。值为 1 的位数和等于 1 + 2 = 3 。
- (1, 3) 和 (3, 1): (1 AND 3) 的二进制表示等于 (01) ,(1 OR 3) 的二进制表示等于 (11) 。值为 1 的位数和等于 1 + 2 = 3 。
所以优质数对的数目是 5 。示例 2:
输入:nums = [5,1,1], k = 10
输出:0
解释:该数组中不存在优质数对。
提示:
1 <= nums.length <= 1051 <= nums[i] <= 1091 <= k <= 60
Metadata
- Link: Number of Excellent Pairs
- Difficulty: Hard
- Tag:
You are given a 0-indexed positive integer array nums and a positive integer k.
A pair of numbers (num1, num2) is called excellent if the following conditions are satisfied:
- Both the numbers
num1andnum2exist in the arraynums. - The sum of the number of set bits in
num1 OR num2andnum1 AND num2is greater than or equal tok, whereORis the bitwise OR operation andANDis the bitwise AND operation.
Return the number of distinct excellent pairs.
Two pairs (a, b) and (c, d) are considered distinct if either a != c or b != d. For example, (1, 2) and (2, 1) are distinct.
Note that a pair (num1, num2) such that num1 == num2 can also be excellent if you have at least one occurrence of num1 in the array.
Example 1:
Input: nums = [1,2,3,1], k = 3
Output: 5
Explanation: The excellent pairs are the following:
- (3, 3). (3 AND 3) and (3 OR 3) are both equal to (11) in binary. The total number of set bits is 2 + 2 = 4, which is greater than or equal to k = 3.
- (2, 3) and (3, 2). (2 AND 3) is equal to (10) in binary, and (2 OR 3) is equal to (11) in binary. The total number of set bits is 1 + 2 = 3.
- (1, 3) and (3, 1). (1 AND 3) is equal to (01) in binary, and (1 OR 3) is equal to (11) in binary. The total number of set bits is 1 + 2 = 3.
So the number of excellent pairs is 5.Example 2:
Input: nums = [5,1,1], k = 10
Output: 0
Explanation: There are no excellent pairs for this array.
Constraints:
1 <= nums.length <= 1051 <= nums[i] <= 1091 <= k <= 60
Solution
#include <bits/stdc++.h>
#include <ext/pb_ds/assoc_container.hpp>
#include <ext/pb_ds/tree_policy.hpp>
#include <vector>
#define endl "\n"
#define fi first
#define se second
#define all(x) begin(x), end(x)
#define rall rbegin(a), rend(a)
#define bitcnt(x) (__builtin_popcountll(x))
#define complete_unique(a) a.erase(unique(begin(a), end(a)), end(a))
#define mst(x, a) memset(x, a, sizeof(x))
#define MP make_pair
using ll = long long;
using ull = unsigned long long;
using db = double;
using ld = long double;
using VLL = std::vector<ll>;
using VI = std::vector<int>;
using PII = std::pair<int, int>;
using PLL = std::pair<ll, ll>;
using namespace __gnu_pbds;
using namespace std;
template <typename T>
using ordered_set = tree<T, null_type, less<T>, rb_tree_tag, tree_order_statistics_node_update>;
template <typename T, typename S>
inline bool chmax(T &a, const S &b) {
return a < b ? a = b, 1 : 0;
}
template <typename T, typename S>
inline bool chmin(T &a, const S &b) {
return a > b ? a = b, 1 : 0;
}
#ifdef LOCAL
#include <debug.hpp>
#else
#define dbg(...)
#endif
// head
class Solution {
public:
long long countExcellentPairs(vector<int> &nums, int k) {
sort(all(nums));
nums.erase(unique(all(nums)), nums.end());
auto f = vector<int>(65, 0);
auto g = vector<int>(65, 0);
ll res = 0;
for (const auto &n : nums) {
int x = __builtin_popcountll(n);
f[x]++;
}
for (int i = 1; i < 65; i++) {
g[i] = g[i - 1] + f[i];
}
for (int i = 1; i < 65; i++) {
res += 1ll * f[i] * (g[64] - g[max(0, k - i - 1)]);
}
return res;
}
};
#ifdef LOCAL
int main() {
return 0;
}
#endif